存储的访问速度是根据业务场景来看,即要读取效率高,又要写入效率高,那肯定是内存的操作。但内存非常昂贵,如图1各种介质的性能和成本对比:
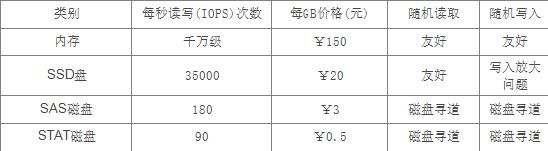 表1 存储介质对比
表1 存储介质对比
相对磁盘来说,内存非常昂贵,所以大量研究人员对存储的优化做了大量工作,并构建了很多数据结构,使得数据更快的访问。对于大数据的场景,一般常使用下面几种存储引擎方式组织数据。
1 哈希(hash)索引
Hash索引是存储常见的一种索引方式。因Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
对于随机读取,哈希索引应该是最快的获取数据的方式,但哈希的随机写受很大的限制,对于机械磁盘,随机写会造成磁头寻道的时间更长,而对于固态硬盘,因为写放大的问题,往往写比读慢。哈希索引不适合连续读取和写入的场景,仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
像DBM、redis等使用哈希索引加快查询、写入速度。
2 B树(B-Tree)索引
说到B树,一般会先了解一下平衡二叉树。
平衡二叉树具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。因为每个节点下最多只有两个子节点,所以想找到某个数据,必须从其中一个子节点取出他的两个子节点来判断大小,这个过程重复的次数,就是树的高度。检索时,高度一般都良好地维持在O(log2n),大大降低了操作的时间复杂度。
平衡二叉树结构的好处是没有空间浪费,但坏处是需要取出多个节点,且无法预测下一个节点的位置。这种取出的操作,在内存中速度很快,但若到磁盘,那么就意味着大量随机寻道,访问速度就慢死了。
B树则在其构建过程中引入了有序数组,从而有效的降低了树的高度,且一次能取出一个连续的数组,因此检索数据时,在磁盘上比取出与数组相同数量的离散数据,要快得多。因此磁盘上基本都是B树索引结构。
但B树结构与二叉树相比,会耗费更多的空间。在最恶劣的情况下,要有几乎是元数据两倍的格子才能装得下整个数据集(当B树的所有节点都进行了分裂后)。
B+树则是B树的增强版本,满足下列特征:
(1)有n棵子树的结点中含有n个关键字。
(2)所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身关键字的大小自小而大顺序链接。
(3)所有的非终端节点可以看成是索引部分,结点 中仅含有其子树(根结点)中的最大(小)关键字。
B+树通常有两个指针,一个指向根结点,另一个指向关键字最小的叶子结点。因些,对于B+树进行查找两种运算:一种是从最小关键字起顺序查找,另一种是从根结点开始,进行随机查找。如图2-1所示:
 图2-1 B+树示意图
图2-1 B+树示意图
常见的是B+树索引,也是数据库技术领域常用到的加速数据查询的方式,对顺序读取和顺序写入有优势,对随机读取和随机写入的支持性也很好,机械磁盘则靠磁头寻道,故B+树索引随机读取、随机写入想对较差,而固态硬盘的随机读取想对较好,而随机写入随写入放大受到影响。
像MongoDB、mysql等,都使用B+树索引加快存储读取写入速度。
3 LSM树索引
上述提到B+树索引在随机写入的时候相对较差,怎么从数据结构上解决这个问题呢?当今使用面向顺序写的树的结构来提升写性能。一般比较流行的有COLA(Cache-Oblivious Look ahead Array)和LSM(Log-structured merge Tree)两类数据结构。这里主要说日志结构的合并(LSM)树索引。
LSM树索引其核心思想就是放弃部分读能力,换取写入的最大化能力,即若机器内存足够大,不需要一旦有数据更新就须将数据写入到磁盘中,先可以将更新的数据驻留在内存中,等到积累足够多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘中。读取时需要合并磁盘中历史数据和内存中最近修改操作。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能,如下图3-1:
 图3-1 内存和磁盘中的LSM树
图3-1 内存和磁盘中的LSM树
另外,可以通过Bloom filter在一个小的有序结构里判断是否有那个数据,避免了二分查找。
常见的LSM树索引存储有leveldb、hbase等。
4 Bitcask
Bitcask是一种日志型键值模型。所谓日志型,指它不直接支持随机写入,是将随机写入转化为顺序写入,像日志一样支持追加操作。Bitcask有两个好处:
(1)提高随机写入的吞吐量,因为写操作不需要查找,直接追加即可。
(2)若使用固态硬盘,写入放大的问题能够有效的避免。
Bitcask中存在3种文件,包括数据文件,索引文件和线索文件(hint file, 姑且就叫线索文件吧)。
数据文件存储于磁盘上,包含了原始的数据的键值信息;数据文件以日志型只增不减的写入文件,而文件有一定的大小限制,当文件大小增加到相应的限制时,就会产生一个新的文件,老的文件将只读不写。在任意时间点,只有一个文件是可写的,在Bitcask模型中称其为active data file,而其他的已经达到限制大小的文件,称为older data file,如下图4-1:
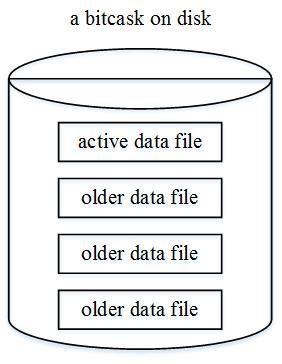 图4-1 Bitcask的数据文件
图4-1 Bitcask的数据文件
文件中的数据结构非常简单,是一条一条的数据写入操作,每一条数据的结构如图4-2所示:
 图4-2 Bitcask的数据文件结构
图4-2 Bitcask的数据文件结构
索引文件存在于内存,用于记录记录的位置信息,启动Bitcask时,它会将所有数据的位置信息全部读入一个内存中的哈希表,也就是索引文件;其作用是通过key值快速的定位到value的位置,如图4-3所示:
 图4-3 Bitcask的数据结构
图4-3 Bitcask的数据结构
线索文件(hint file)并不是Bitcask的必需文件,如果我们不做额外的工作,那么在初始化时重建hash表时,就需要整个扫描一遍全部的数据文件,若数据文件很大,这将是一个非常耗时的过程,因此在生成一份数据文件的同时,Bitcask鼓励生成一份线索文件,这样在重建hash表时,就不需要再扫描所有数据文件,而仅仅需要将线索文件中的数据一行行读取并重建即可。极大的提高了利用数据文件重启数据库的速度。
像riak、beansdb就属于Bitcask索引结构类型。
5 跳表(Skiplist)
跳跃表是一种随机化数据结构,基于并联的链表,其效率可以比拟平衡二叉树,查找、删除、插入等操作都可以在对数期望时间内完成,对比平衡树,跳跃表的实现要简单直观很多,如下图5-1:
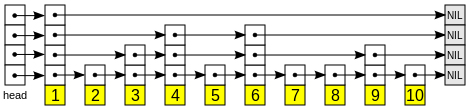 图5-1 Skiplist数据结构
图5-1 Skiplist数据结构
像redis中有一种数据结构叫zset,就是属于跳表。
6 总结
总在来说,存储访问是根据不同的场景去制定不同的数据结构索引,利用本身存储硬件的特性达到最优的结果。每种索引可以根据业务特点做特定的优化,形成各种各样的存储引擎。
