发现Fedora44的升级体验非常棒!
Continue reading Fedora44 升级体验.
好久没有更新Movable Type 版本了,五一期间闲下来,顺便给升级了一下,8.0.2-> 9.1.1。
本指南记录了从OrbStack备份镜像文件(data.img.raw)中恢复Docker卷和容器的完整过程。
✅ Docker卷:fedora4cnangel (2.2GB)
✅ 容器:fedora43 (基于自定义Fedora 43镜像)
✅ 用户配置、开发环境和历史数据
备份中还包含以下卷(未恢复):
elasticsearch_certs (28KB)
elasticsearch_esdata01 (6.2MB)
Milvus官方提供了单进程版本安装方式和K8s()的安装方式,但这种方式往往不利于生产环境的部署。
Milvus从2.6.0开始,其角色进行了大幅度调整,其架构由:
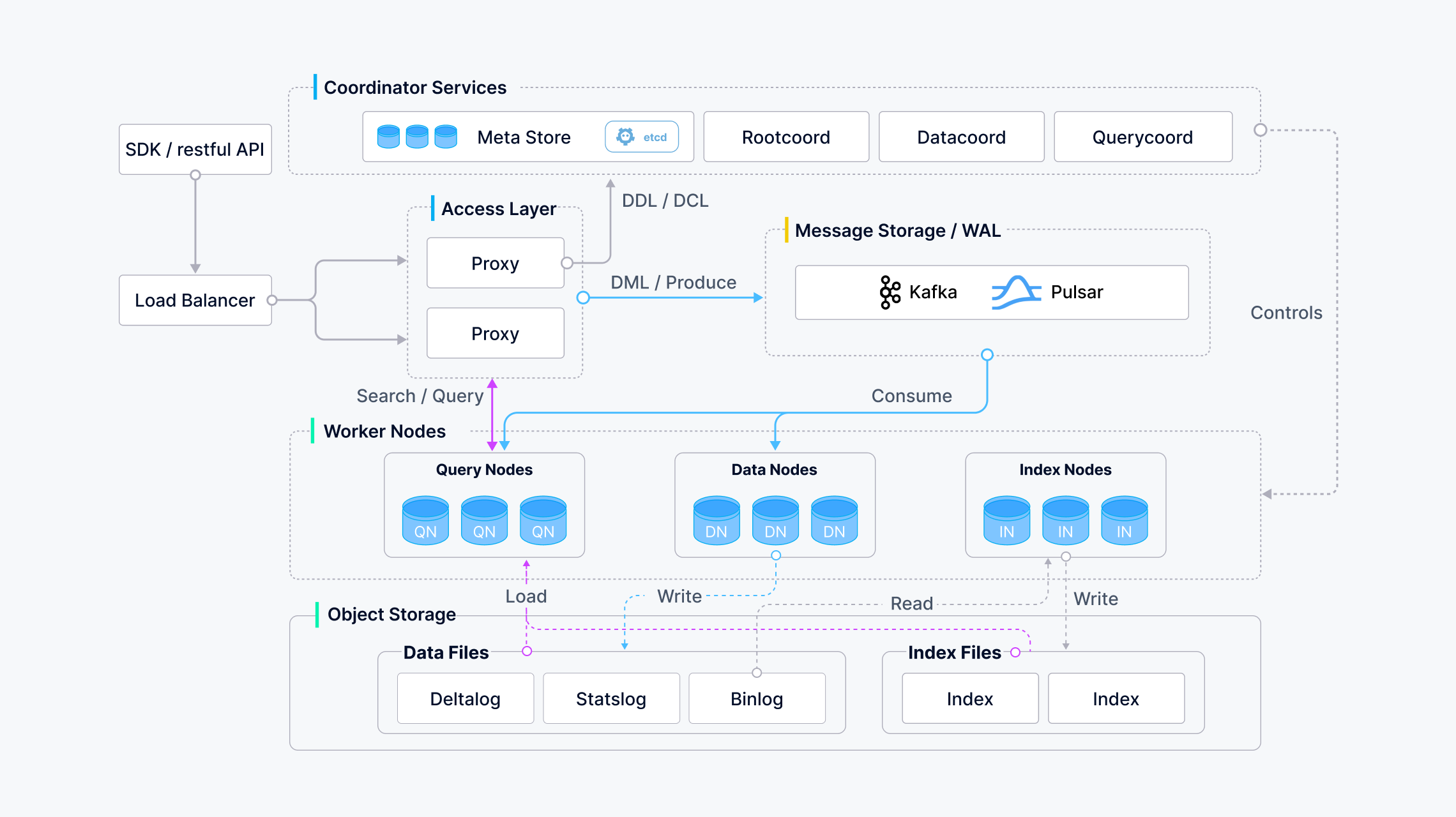
演化成:
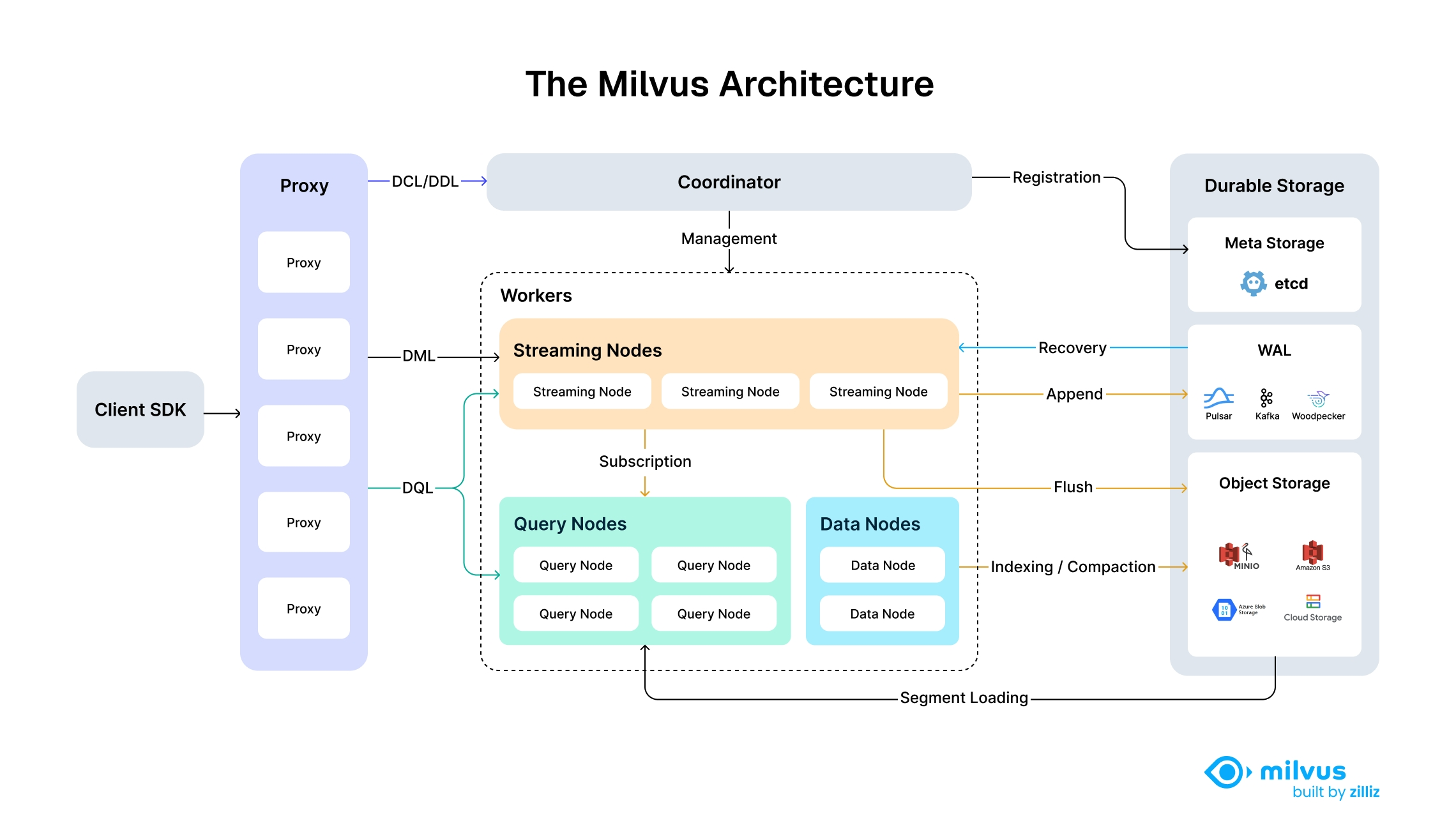
其部署方式也发生了变化。
写这篇文章希望能够细化到Milvus的部署和配置信息,并将Milvus相关依赖明细化,避免黑盒方式使用。
新的发布人杰夫·斯帕莱塔公告了这一消息,敢于尝新的伙伴们赶紧去试试吧
随着神舟十九的飞船返回,fedora42也即将发布。
一些边界不断打破,是促进创新还是倒退?
Fedora Linux 41 默认为命令行包管理工具 DNF 的新主要版本。此版本更快、更小,并且需要更少的支持包。这消除了容器和内存受限系统对"microdnf"的需求----现在,可以跨容器、服务器、桌面和设备使用相同的 DNF。
Fedora Workstation 41 基于 GNOME 47。请阅读 Fedora Workstation 41 的新功能 了解详情。特别是对于命令行用户,Fedora41已将默认终端更改为 Ptyxis。它更轻量级,但也有一些不错的新功能。(如果用户需要 GNOME Terminal 提供的一些灵活性,它仍然存在。)
另外,目前还提供了几个重要的发布日错误修复和安全更新。如果用户从早期的 Fedora Linux 版本升级,将获得它们作为其中的一部分。对于新安装,请务必尽快检查并应用更新。
当打开以https开头的网页时,如果其图片、js或接口是http协议,正常浏览器是打不开该网页的。
当Clickhouse服务器强制关闭、异常断电、以及数据拷贝时等,导致Clickhouse数据损坏,服务无法启动,提示:
<Error> Application: DB::Exception: Suspiciously big size (4 parts, 1.05 GiB in total) of all broken parts to remove while maximum allowed broken parts size is 1.00 GiB. You can change the maximum value with merge tree setting 'max_suspicious_broken_parts_bytes' in <merge_tree> configuration section or in table settings in .sql file (don't forget to return setting back to default value): Cannot attach table `ads`.`xxx_tbl` from metadata file /var/lib/clickhouse/store/
需要在/etc/clickhouse-server/config.d配置中增加max_suspicious_broken_parts.xml文件,内容如下:
<?xml version="1.0"?>
<yandex>
<merge_tree>
<max_suspicious_broken_parts>1000</max_suspicious_broken_parts>
<max_suspicious_broken_parts_bytes>2147483648</max_suspicious_broken_parts_bytes>
</merge_tree>
</yandex>
然后启动Clickhouse即可:
systemctl start clickhouse-server.service








