向量数据库(Vector Database)。
传统数据库的局限
传统关系型数据库擅长精确匹配:WHERE name = 'Alice'。但面对以下场景时力不从心:
以图搜图:找出"视觉上相似"的图片
语义搜索:用一句话找出"含义相近"的文档
推荐系统:找出"行为上相似"的用户
这类问题的本质是相似性搜索,而不是精确匹配。
向量与嵌入(Embedding)
AI 模型(如 BERT、CLIP、text-embedding-ada-002)可以将非结构化数据转化为高维浮点数向量,称为 Embedding:
"今天天气真好" → [0.12, -0.87, 0.34, 0.91, ...] # 768 维语义相近的内容,其向量在空间中的距离也更近。相似性搜索就转化为了近似最近邻(ANN, Approximate Nearest Neighbor)搜索问题。
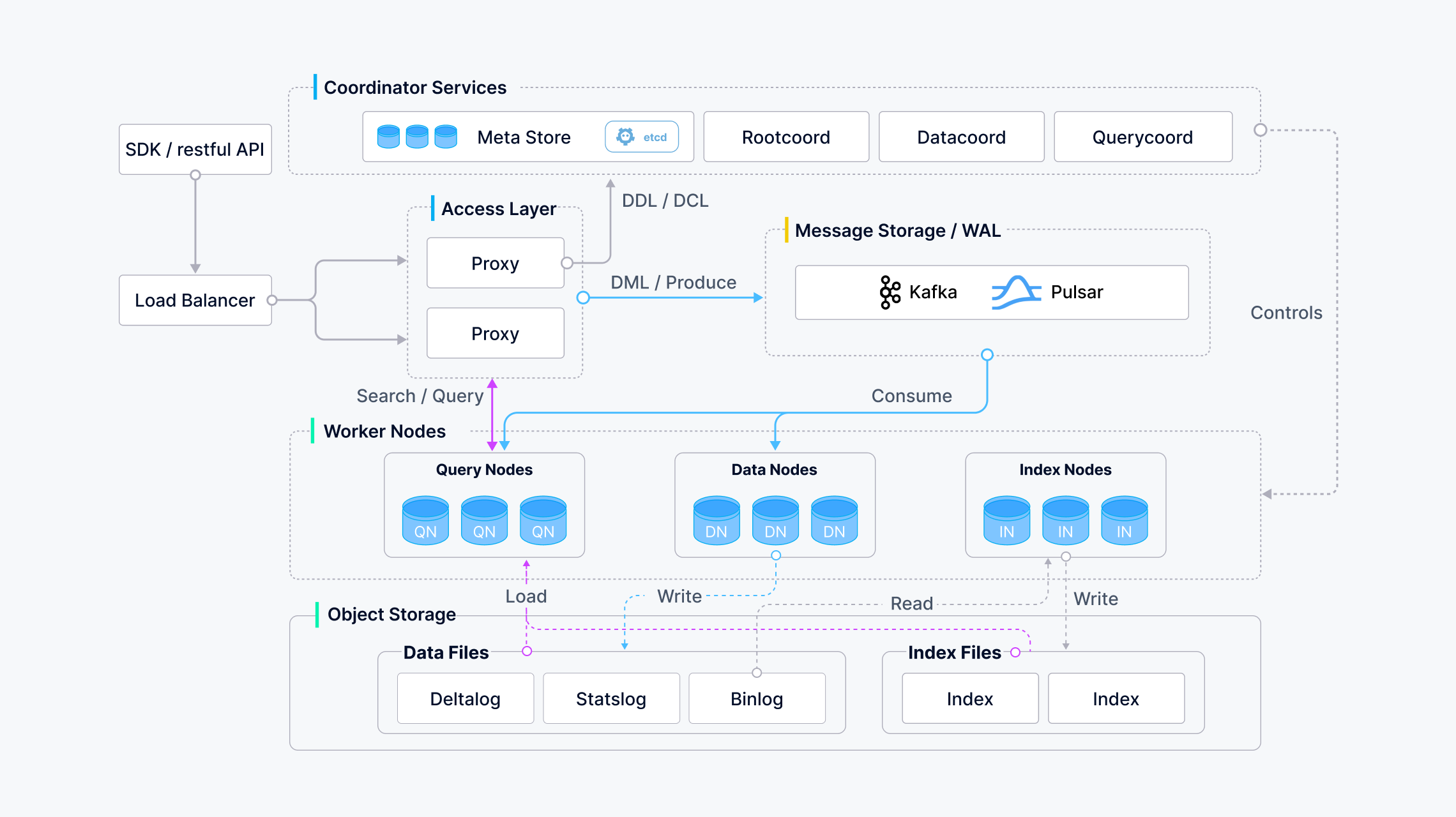
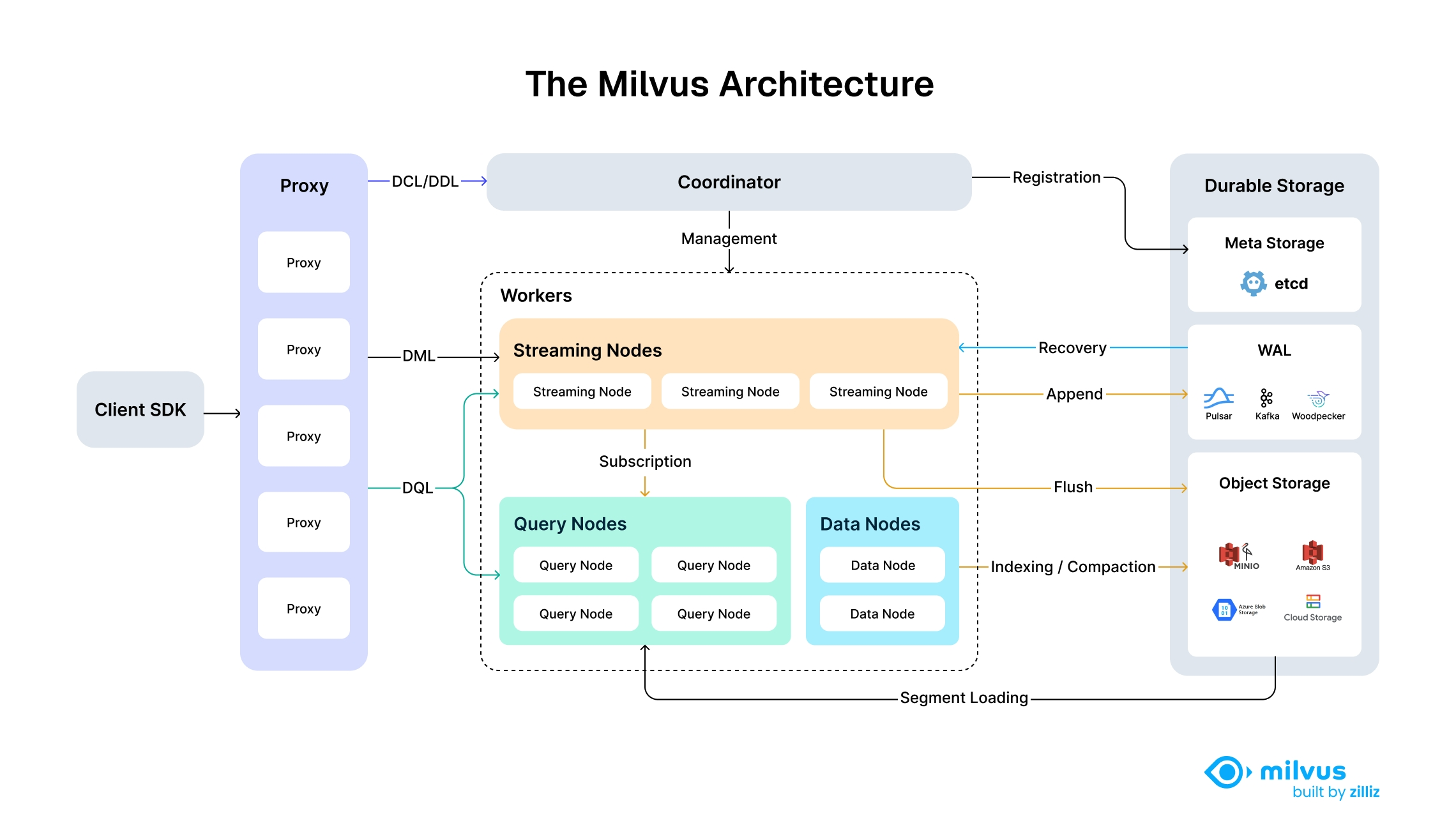
向量数据库的核心能力
原始数据 → Embedding 模型 → 向量 → 向量数据库存储 → ANN 查询 → Top-K 结果| 能力 | 说明 |
|---|---|
| 高效 ANN 搜索 | 亿级向量毫秒级返回 |
| 多种索引支持 | IVF、HNSW、DiskANN 等 |
| 标量过滤 | 向量搜索 + 条件过滤组合查询 |
| 水平扩展 |
Continue reading 向量数据库与 Milvus:从原理到性能调优实践.