什么是Double Array Trie
- Double Array Trie是TRIE树的一种变形,它是在保证TRIE树检索速度的前提下,提高空间利用率而提出的一种数据结构,本质上是一个确定有限自动机(deterministic finite automaton,简称DFA)。
- 所谓的DFA就是一个能实现状态转移的自动机。对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符,它都能根据事先给定的转移函数转移到下一个状态。
- 对于Double Array Trie(以下简称DAT),每个节点代表自动机的一个状态,根据变量的不同,进行状态转移,当到达结束状态或者无法转移的时候,完成查询。
什么是Double Array Trie
- Double Array Trie是TRIE树的一种变形,它是在保证TRIE树检索速度的前提下,提高空间利用率而提出的一种数据结构,本质上是一个确定有限自动机(deterministic finite automaton,简称DFA)。
- 所谓的DFA就是一个能实现状态转移的自动机。对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符,它都能根据事先给定的转移函数转移到下一个状态。
- 对于Double Array Trie(以下简称DAT),每个节点代表自动机的一个状态,根据变量的不同,进行状态转移,当到达结束状态或者无法转移的时候,完成查询。
DAT结构
DAT定义
- DAT是采用两个线性数组(base[]和check[]),base和check数组拥有一致的下标,(下标)即DFA中的每一个状态,也即TRIE树中所说的节点,base数组用于确定状态的转移,check数组用于检验转移的正确性。因此,从状态s输入c到状态t的一个转移必须满足如下条件:
base[s] + c == t
check[base[s] + c] == s
- DAT也可如下描述:
- 对于给定的状态s,如果有n个状态(字符c1,c2,...,cn)的转移,需要在base数组中找到一段空位t1,t2,...,tn,使得t1-c1,t2-c2,...,tn-cn都为base数组中下标为s的值,注意此处的t1,t2,...,tn不一定在base数组中连续;
- 对于转移的状态t1,t2,...,tn,其作为下标时,check[t1],check[t2],...,check[tn]的值都为状态s;
- 为了便于理解,这里有一个256叉树的图(准确的说是26叉树,但是图画得不好,暂且我们把它当作256叉树吧)。
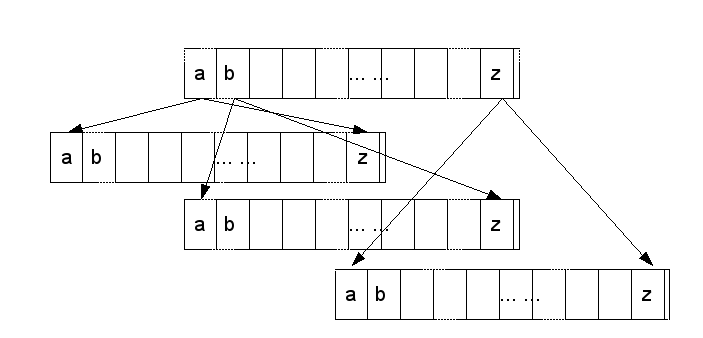
- 图中最顶端有256的父节点,每个父节点都有256个子节点;那么无论汉字和字母,都可以分布在256个子节点上,但是如果词语只有app和apple以及banana三个词语,那么256个父节点显得有些浪费,实际上只需要2个父节点就可以了。
- 如果节点的类型为整型,我们把所有的节点进行编号的话,且直接采用词语的首字母ascii码来直接作为节点,97,98这两个父节点会使用到,其余的父节点是多余的,使用一个空指针即可。
- 根据256叉树的定义,97和98也会有256个子节点,但是词语的第二个字母显示,97的下一个节点只有一个p(112)节点,98的下一个节点只有一个a(97)节点,则其余的节点仍然为空,这样,由于树型的算法的复杂度为On,即最多n次匹配即可完成一次查找,而我们可以省略不用的节点,降低空间的空闲率。
DAT匹配
基于上述定义,DAT的匹配过程如下:假设当前状态为s,对于输入的字符c有:
t = base[s] + c;
if check[t] = s then
next state = t;
else
fail;
endif
DAT匹配的过程相对简单,很容易理解。
DAT构造
- 首先我们需要了解一下DAT的内存管理
- 在DAT的构造过程当中,一般有两种构造方法:
- 已知所有词语,静态构造双数组;
- 此方法构建时,是将所有词语全部放入到内存,对词语中所有的父节点和其下的子节点分别进行排序(一般为ASCII码排序),找出最初的父节点数目和有多少个不同的子节点数,方便对内存进行分配。这样的优点是找到放置子节点空间完全能够容纳子节点,以后不需要进行扩充,相对复杂度较低,且构建速度相对很快。缺点是以后添加词语不太灵活,每次需要重新构建;
- 动态输入词语,动态构造双数组。
- 当n条词语准备构建双数组时,先以添加一条词语cat为例,双数组中base[1024]数组根节点为0(默认值,当然根据“个人爱好”可以随意指定),下标为0,为词语cat的首字符"c“(99)找一个合适的位置,比如位置100,即:
base[0] = 100;
- 此处那么在base[100]的位置下,加上字符"c"的ascii值得到下一个状态(t)的位置(199),然后在一个合适的位置(空闲的位置)197,使得
base[199]+'a'=197;
- 那么状态(t),即base[199]的值可以通过上述公式得到仍然为100
- 值得注意是,在状态(f),目前即字符"t",结束时,其value值可以做如下处理,如果状态(f)结束,没有子节点,则
base(f)=-1 * f;
- 如果状态(t)结束,仍然有多个子节点,那么其base数组标记为
base(f)=-1 * base(f);
- 当输入第二条词语camera时,仍然按照上述方式进行,当进行到字符a时,字符a位置的下标为197,检查check[base[197]+'m']是否为空位。
- 如果为空位,则base[197]的值仍然可以为100;
- 否则需要重新寻找两个空位位置Ψ(base[197]+'m'),λ(base[197]+'t'),使得 base[base[197]+'m']=-1(-1标记为空位状态,"m"为camera的第三个字符)和 base[base[197]+'t']=-1("t"为cat的第三个字符),即第二级节点a后面的两个新节点能有位置存放新的偏移量,并使得 check[base[197]+'m']=197和check[base[197]+'t']=197即可,那么base[197]的值需重新指向到新的位置(Ψ+λ-'m'-'t')/2。
- 接着继续重新构建下面新两个节点的DAT结构,且第一个节点的结构构造完成后,需要清除原来的构建。
- 动态构造双数组能够很方便的动态插入词语,不需要重新构造整个TRIE树,但是实现的逻辑相对复杂一些。
- 已知所有词语,静态构造双数组;
- 若初始状态申请的数组大小不足时,需要进行扩充,并将原来的数组拷贝到新增大的数组上,且原来的数组一般需要进行内存释放,如下图:
- 在DAT的构造过程当中,一般有两种构造方法:

- DAT构造中,check数组需要指向父节点,即base数组中父节点的下标即可,这里有一副简图,描述了构造DAT双数组的方式:

DAT改进方案
- DAT相对普通TRIE树来说,提高了空间的利用率,但是空间利用率还不是最好的。
- 比如单词elephant(8个字符),如果所有词语当中只有一个以e开头的词语,一般我们实现trie的结构写成
struct BC_st
{
int base;
int check;
};
- 那么整个词语在DAT中占用的空间是4*2*8=64字节。其实存储没有必要浪费那么多空间,在DAT结构里面,完全可以以7个字节来存储lephant,查询的时候lephant实现字节查找就可以了。
- DAT是一个树型的结构,不断发散的结构,如果在对面实现一个同样的结构,相对来说,会减少一半的空间体积,如图所示:

- 当然上述的结构已经有人实现过,实现比较复杂。
- 另外,在DAT双数组当中,有很多的空闲空间未得到充分利用,可以通过链表将未使用的空间串联起来,更加合理的利用,提高数据密集程度。
